Cache对于现代处理器提升性能有多重要就不多说了,最近看到这方面的练习,正好来实践下。
原文来自伯乐在线请猛击这里
第一个例子解释cache一次从memory读取的大小,这是可能与cache line不一致的,具体多少可以通过统计得出。
原文使用了C#例子,正好最近学习python,这里来模拟下。
1. 基于list的测试
1 | buf_len = 64*1024*1024 |
最直接的模仿就是list,可惜结果差3个数量级,看下图: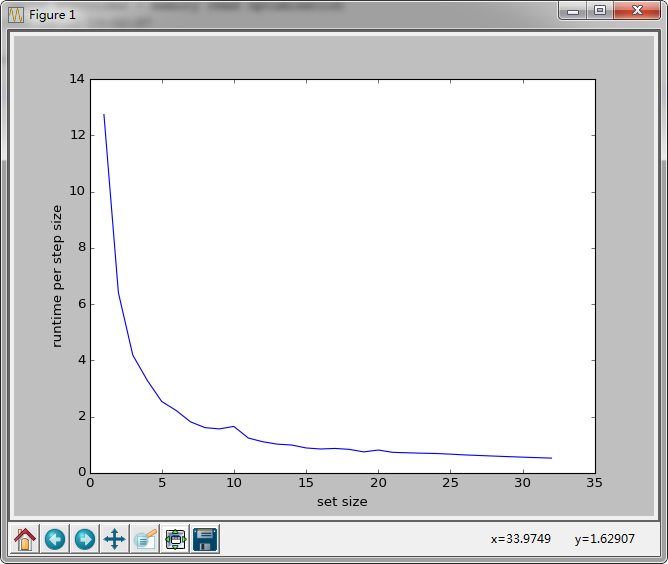
步长为1时,遍历一遍需要12秒之多,例子中是80ms,大家感受下,cache肯定没有发挥作用。事实上随着step加倍,运行时间减半,完美的指数函数,完全忽视cache。。。
事实上python中list跟C/C++中的array并不一样,是一个包装起来的行为类似array的对象,其占用的size远远超过元素本身之和。>>> sys.getsizeof([])64
这里其实已经做过优化,并没有使用for ... in ...这样的pythonic遍历方式,因为产生一个索引list会占用同样多的memory,而且也有memory read的cache问题。难道用python做性能测试就是个杯具。。。
update @2015-09-20
xrange正是为这样的迭代所优化,它不会实际产生一个遍历list,而是按需生成数据,因此内存效率和性能都大有改善。PS:range在python3中升级成为generator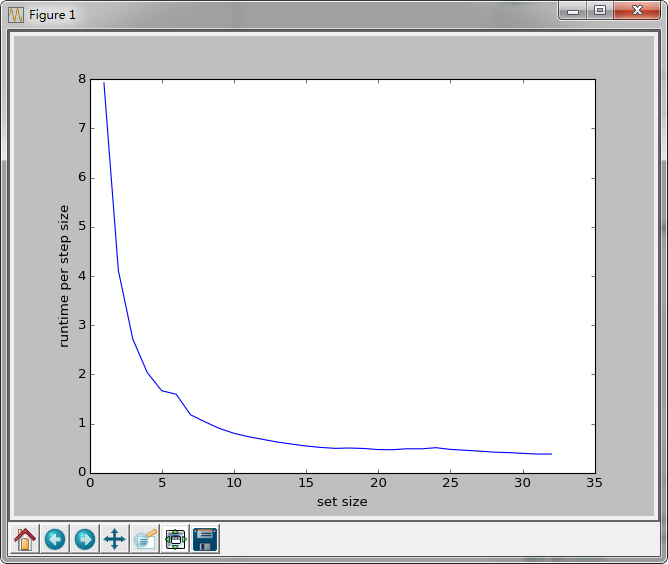
可以看到1步遍历提高了约33%的性能,遍历一遍需要大约8秒(缩短4秒),虽然离cache的结果还差得远,但就遍历来说是个很好的优化。
2. 基于array的测试
既然list不够快,那换能够直接接触memory的array。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from array import array
buf_len = 64*1024*1024
buf = [0] * buf_len
buffer = array('i', buf)
def calc_at_every(step):
for i in xrange(0, buf_len, step):
buffer[i] *= 3
if __name__ == '__main__':
from timeit import Timer
results = []
for i in range(1, 33):
#print "test starts for step %d" % i
t = Timer("calc_at_every(%d)" % i, "from __main__ import calc_at_every")
#print t.timeit(1)
results.append(t.timeit(1))
import matplotlib.pyplot as plt
plt.plot(range(1, 33), results)
plt.ylabel('runtime per step size')
plt.xlabel('set size')
plt.show()
结果更差。。。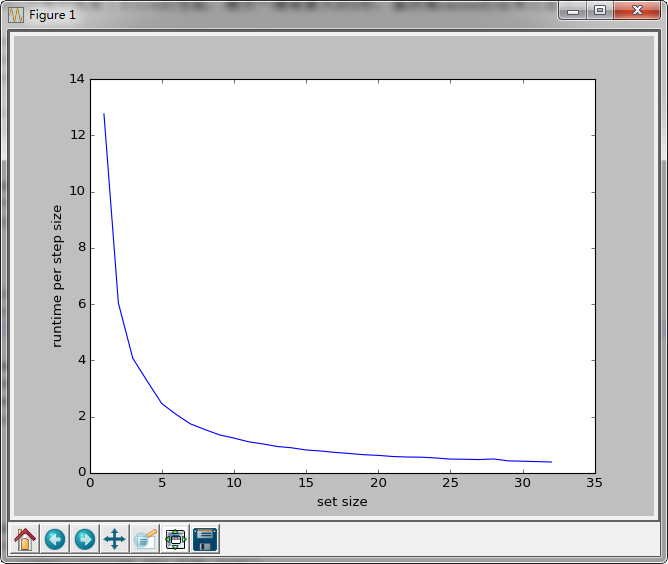
3. 基于numpy.array的测试
1 | from array import array |
惨不忍睹。。。
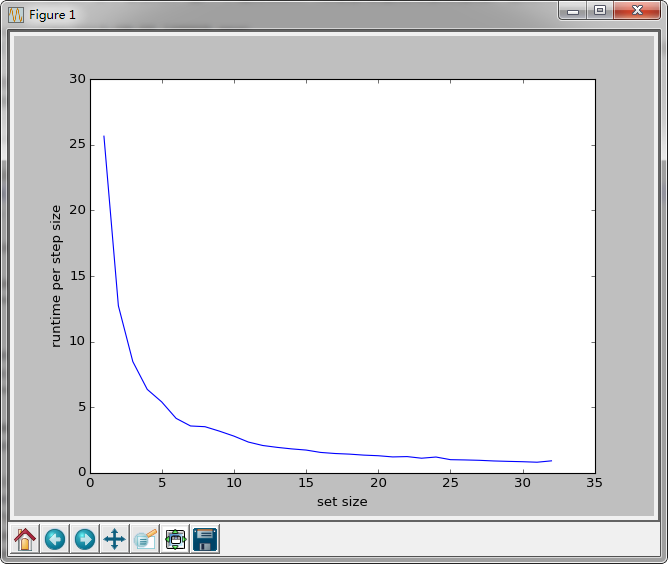
to be continued